

python+pyocr+Tesseractを利用する
pythonにはいろいろとライブラリがあるようで、改めてすごさを認識させられる。が、結論から言うと使うには相当シビア。カメラをしっかり固定してもどうだろうかという性能。
実用化可能な現実的なライン
現在の発展した技術を利用すれば余裕で可能(というかスマホにすらある)にもかかわらず。昭和レベルの働きをしているため、そこを大きく変えるのであれば、これが現実的な気がする(謎の文章)
覚書き(課題)
以下のサイトを参考にした

する前は本当にひどかった…
※2値化のところはファイル名が上でimg_grayとなっているのでgrayでなくimg_grayのはず
残りを流れに沿ってやってみたが、何も認識されない。
2値化が面倒。閾値が画像によって変わる。自動で決めよう日にはひどいことになる。
Tesseractはどうやら相当シビアなようで、わずかな角度のずれで読み取れなくなる。許容されるのは1度くらいか?
このため、
①2値化を適切に行われるよう手動で行う
②モルフォロジー変換は私の用意した画像では2くらいの方がうまくいくnp.ones((5,5),np.uint8) の5のところ
③角度を補正する(自分で取得した値の場合)
④tesseract_layout=8のほうがいいみたい(6ぽいが8の方がうまくいく)
辺りを行うことで、やっとこさうまくいくようになった。
スポンサーリンク
結論(ちょっと使い物にならない)
この方針で進めていくのか、別ルートを用いるのか、だいぶ悩むところ。角度のずれはカメラの固定次第のため、少なくとも2値化は自動できれいに行う必要がある。
画像は自前のが使えた方がよさそう。
SSOCRも気になるところだが、そもそも機械学習的なものを勉強したいため、少し別方向から攻めてみようと思う。
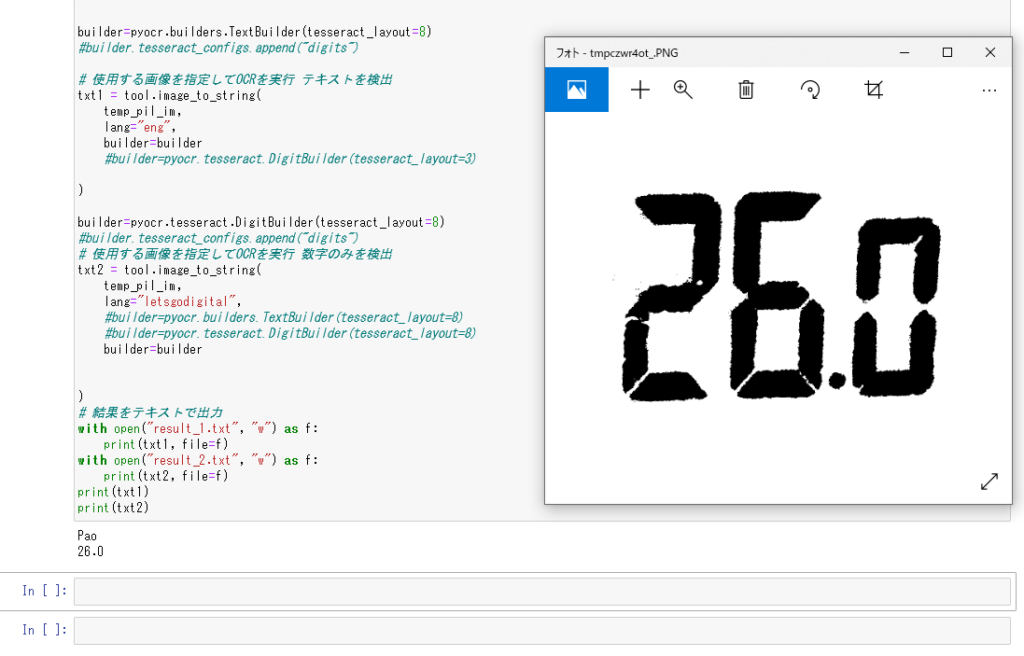
出力2行目は言語をletsgodigitalにしたものの結果。

コメント