

IEならまだしもedge
諸事情によりedgeで特定のページを開き、ログインし、特定のデータを拾ってきてエクセル等に整理して並べる必要性が出てきた。IEであればいろいろと情報も手段もあるが、edgeとなるととてつもなく情報量が少なく、素人の私にはなかなか壁が高いが、毎度毎度面倒すぎるため、勉強がてら作成することにした。
使用環境(暫定)
OS:Windows10
言語:python(Anaconda)
ブラウザ:edge
操作方法:selenium+BeautifulSoup
データ出力:excel
操作、入力画面:PySimpleGUI
とする
覚書き兼手順
Anacondaのインストール(passを通しておく)
edge用webdriverをインストールする
pip3でいろいろインストール
jupyterNotebookで書いていく
guiを立ち上げ他はモジュールにする。
読み込みが面倒なので
import importlib
importlib.reload(ba)#対象モジュール
を使う
最初適当に固定値で作ったが結局エクセルに書き込むのにx座標とy座標を渡す形をとったが、csvかなんかを読み書きした方がいい気もするが、使うのは私だけでもない以上、現状維持
エクセルのセルが空でないという条件は if cs.cell(y,x).value not is None:
のようになる。明らか慣れてない。
現在のネック
①ボタンクリックやテキスト入力しようとした際element not interactableと出てくるものがある
いや、明らかにあるのだが。.is_displayed()で確認してfalseが返ってきているからよくないとかなんとか。
②やるだけ
やるだけの時間がない。がGW入ったので一気に作る。いったん終わり
③ログイン
悩ましい要素。idとパスを打つか覚えておくか
諸事情によりここまでやっておきながら手打ちを選択せざるを得ない気がする。
とはいえひとまずエクセルにidとpassを保存し、そこから読み出し。
④スクレイピングの検索条件
典型が難しい。参考資料がweb上に山ほどあるのが救い
進捗と課題
| 機能 | 進捗 | 課題や備考 |
| ブラウザ遷移 | 完了 | リダイレクトに難あり |
| ログイン | 完了 | エラーが発生することがある |
| ページデータ取得 | 完了 | |
| リンクの取得 | 完了 | 適切な取得方法の選択が必要 |
| 特定のデータ取得 | 完了 | 目的するものと完全一致させるのは難しい。暫定での作成 |
| エクセルに記載 | 完了 | 特定データの記録 |
| 操作画面作成 | 完了 | tkinterを考えていたがPySimpleGUIがお手軽すぎる |
気合入れたので1日で終わった。
感想
pythonは機械学習以外ですばらしいと初めて思ったかもしれない。ライブラリの性能がおかしい。
方向性を間違っていた気がするので、再度作り直す
前に作成したはいいんですが、中途半端かつ、重要な箇所に理解が及んでいないため、何にも使えないゴミになっていた。方向性を明確にし、再度作り直すことにした。
やりたいこと
⓪edgeを起動し、指定リンク先を開く
①特定の個所をクリックする。
②特定の個所に文字を入力する。
③特定の個所よりテキストを取得する(場合によっては不要)
イメージとしてスクレイピングというよりはタイトルの通り、自動操作が主である。前回はスクレイピングに近い内容で作成していたのと要素指定が確定しておらず、よくわからないことになっていた。
環境
OS:Windows10
言語:python(Anaconda)
ブラウザ:edge
操作方法:selenium
とする
特定の個所をクリックする
2種類の方法があり、
1.要素を指定してクリックする
2.座標を指定してクリックする
この二つの方法があるかと思いますが、もちろん2の方が面倒で環境に依存するため、まずは1でできるところは1でするべきです。
①要素を指定してクリックする
⓪edgeで指定リンク先を開く部分は以下参考サイトを参照

事前準備としてedgeでクリックしたい画面を開き、F12を押して開発者コンソールを表示します
クリックしたい要素を開き右クリックでコピーを選択し、完全なXpathのコピーを選択します。
element = driver.find_element_by_xpath("ここにコピーしたXpathを貼り付ける")
element.click()これで完成となります。お手軽です。
②座標を指定してクリックする(画像認識を利用)
①が何らかの理由で使えない場合こちらを使うことになります。
座標を指定してクリックする場合、座標を指定するだけでは使用する環境によって動作が不安定になりますし、今回行いたいのは、ただただなぜか①の手法でクリックできないものにも適用したいのですが、それとともに出現する場所がまちまちな特定の色の個所をクリックしたいものになります。
大まかな流れとして、
1.ブラウザ画面をキャプチャし、対象箇所の色を確認する
2.画像認識により対象箇所の座標(点ではなく大きさのあるもの)を取得し、クリックする座標(点)を計算し、取得する
3.その座標をブラウザ画面よりクリックする。
と一気に面倒になりますが、ブラウザ画面内にあればどこに表れようとクリックできる(はずです)。
ブラウザ画面をキャプチャし、対象箇所の色を確認する
参考サイトからの変更点はすでに所持している画像でなく、そのまま画面をキャプチャしてビットマップで保存し、
それを利用して色を確認する。ビットマップの方が画像が重いが精度がいい。
またこの後の処理のため、RGBでなく、HSVで取得する。最初いちいち色見本サイトでHSVに変換していたのがバカみたいだ。

import cv2
import os
from PIL import ImageGrab
ImageGrab.grab().save('IMG/screenshot.bmp')
img = cv2.imread('IMG/screenshot.bmp', cv2.IMREAD_COLOR)
window_name = 'img'
imgBoxHsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
def onMouse(event, x, y, flags, params):
if event == cv2.EVENT_LBUTTONDOWN:
crop_img = imgBoxHsv[[y], [x]]
H_val = crop_img.T[0].flatten().mean()
S_val = crop_img.T[1].flatten().mean()
V_val = crop_img.T[2].flatten().mean()
print("H: {}, S: {}, V: {}".format(H_val, S_val, V_val))
def my_makedirs(path):
if not os.path.isdir(path):
os.makedirs(path)
dirpath= "./IMG"
my_makedirs(dirpath)
cv2.imshow(window_name, img)
cv2.setMouseCallback(window_name, onMouse)
cv2.waitKey(0)画像認識により対象箇所の座標を取得し、クリックする座標を取得する
ここが最大の難所となる。が、ライブラリ(openCV)が強く、割と柔軟に行けるはず。以下の3つが参考にしたサイト



import cv2
import numpy as np
def frame_search(img_pass):
img = cv2.imread(img_pass)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# HSV範囲(閾値を変えたい場合は下記の範囲を変更すること。)
#クリック証券赤色ボタン用(口座開設)
#lower = np.array([1,240,170])
#upper = np.array([2,250,200])
#クリック証券青色枠用(ログイン)
lower = np.array([105,255,174])
upper = np.array([105,255,174])
# 指定色以外にマスク
mask = cv2.inRange(hsv, lower, upper)
res = cv2.bitwise_and(img, img, mask= mask)
# 一旦保存
cv2.imwrite("IMG/mask_color.jpg", res)
#グレースケール化し保存
img_gray =cv2.cvtColor(res,cv2.COLOR_BGR2GRAY)
cv2.imwrite("IMG/mask_gray.jpg", img_gray)
#最近のcv2.findContoursの戻り値はこの2つらしい(ここがずっとエラー出てた)
contours, hierarchy = cv2.findContours(img_gray, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
for i in range(0, len(contours)):
if len(contours[i]) > 0:
# remove small objects(↓の値を変えることで取得したい対象に割と自在に対応できる)
if cv2.contourArea(contours[i]) < 200:
continue
#print(cv2.contourArea(contours[i]))
cv2.polylines(img, contours[i], True, (0, 255, 0), 3)
#重心(クリックする位置)を取得し、マーカーをつける
cnt = contours[i]
M = cv2.moments(cnt)
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
cv2.drawMarker(img, (cx, cy), (0, 0, 0), markerType=cv2.MARKER_TILTED_CROSS, markerSize=50)
print(cx,cy)
# save
cv2.imwrite('IMG/result_polylines.jpg', img)
#対象が1個に絞れていることが前提
return cx,cy
同じような色が多くあるが、ビットマップで比較しているのと色相で指定しているのがよいのか。画像の処理の遷移としては以下のようになる。(jpgでやってた頃はひどい有様で、ログインボタンの検出はあきらめていた。GMOクリック証券の回し者ではないです。)
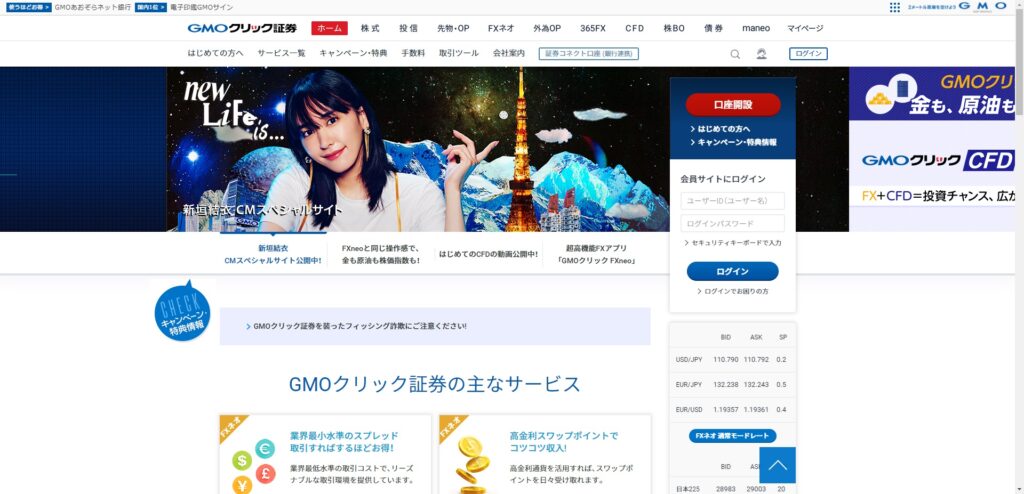


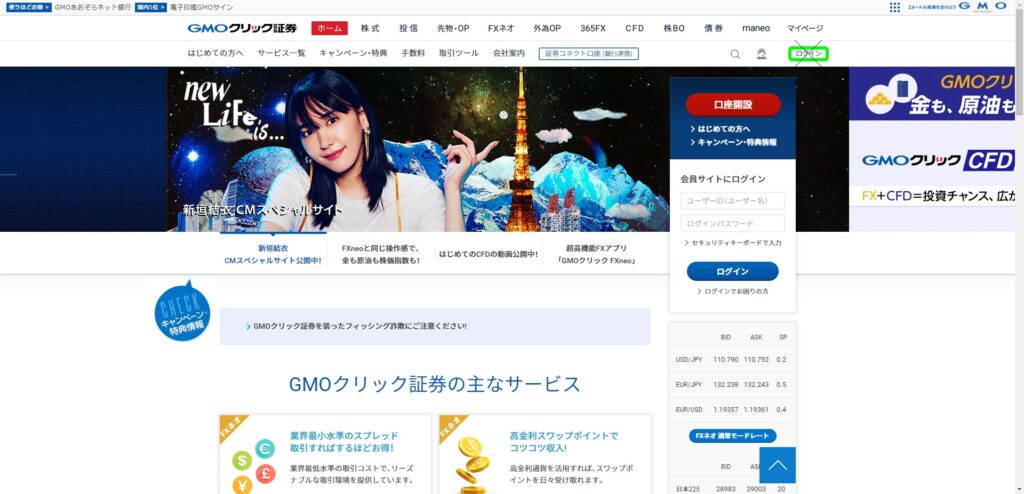
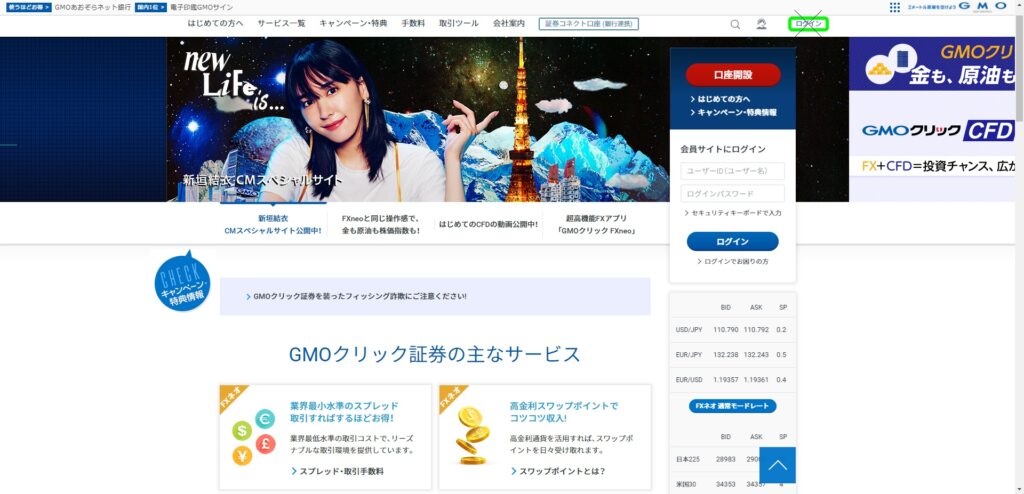
指定座標をクリックする
ここまでくればゴールは目の前。取得した座標をactions.move_by_offset()に渡す
actions = ActionChains(driver)
actions.move_by_offset(offsetx, offsety)
actions.click()
actions.perform()
完成。
次の予定
②特定の個所に文字を入力する。については①を参考にしつつ、
入力だけelement.send_keys()すれば解決のため、問題なし。
③もXpathで指定したところから.textで取得できてしまったので終了
単発動作は問題ないため、複数動作をベタ打ちでなくスマートに行えるようにしたい。
エクセルから読み込み、取得データをエクセルに書き込むようするのがよさそう。
pythonを学ぶのであればUdemyがおすすめです。
コメント